Case study: a browser embedded ontology-driven app for finding time intervals
RDF (Resource Description Framework), SPARQL, ontologies and other Semantic Web Stack technologies are typically associated either with academia or with big corporate data integration projects where knowledge graphs solutions enable what is hard to achieve without the sophisticated modelling functionalities they bring. Knowledge graphs related projects rarely even come into spotlight, mostly being complex, in-house, long-term iterative processes.
The purpose of this article is to demonstrate Semantic Web technologies can be easily used by developers and data engineers to quickly solve concrete problems and accomplish specific tasks. All of this without big budgets, expensive triple stores or PhD in applied logics. There are two motivations behind this goal (inspired by the insightful Ora Lassila’s talks1):
- RDF and SPARQL combined with ontologies can bring what would be hard to achieve using other solutions: self-describing data with accessible semantics. This semantically enriched data enables easier sharing between applications, APIs, people, or creating what recently is being called data products.
- Lack of dedicated tooling, specialized apps, libraries, or services associated with concrete ontologies that could be useful to solve concrete tasks. There are many valuable ontologies published, but they do not come with the necessary tooling that would help developers and data specialists to adapt them and use them in their own context (which might make Semantic Web technologies more popular).
To demonstrate this, we will implement an ontology-driven project and provide an interactive browser embedded demo. In order to avoid restricting our scope to a particular domain, this effort will focus on temporal relations between events and discovering several types of time intervals. After reading this article you will gain an insight on:
- using ontologies with your data
using RDF to produce self-describing data
Project outline
Events data can be found everywhere – from enterprise data warehouses, application servers, IoT devices to application logs stored on your laptop or mobile phone. It can be found in every domain and very often as the input for various analytics processes. Performing advanced analytics tasks with raw event data might be difficult when discovering the temporal relationships between events is required (for example checking chains of overlapping events). Let us consider enriching the raw event data with relationships defined in a publicly available ontology and see how the generated RDF dataset could help us with further processing and sharing of our data.
Our goal is to transform an input dataset consisting of CSV records (or RDF triples) with start and end timestamps/dates into a new RDF dataset which maps the events from the input against each other using basic temporal relationships like temporal overlap, containment, etc. When given such a task one must decide whether to use an existing ontology or create a new one.
Choosing an ontology
(You may skip this section if you are an experienced ontologist).
An ontology describes the semantics of a given domain by defining properties and concepts and the relationships between them in a way that can be understood and shared by applications and people involved. A useful, well-designed ontology provides not only a vocabulary but also building blocks for creating data-driven applications and can be used as an artifact in software development. This is because the ontology-defined axioms, concepts and rules are also data which can be consumed and manipulated by application code.
It is recommended to look for an existing ontology to avoid reinventing it and to use something that was already successfully applied in a commercial or community project. A useful domain ontology2 should:
- Support reusability in different contexts
- Enable partial usage of its content (cherry picking)
- Feature modular implementation to cover various aspects in case of a wider or complex domains
- Contain natural language descriptions of the introduced concepts understandable to domain experts and its technical users (developers, data specialists, consultants, etc.)
- Avoid unnecessary dependency on top-level ontologies
Software developers would quickly realize those criteria are similar to the ones related to choosing an appropriate software library for their project. In fact, many high-quality OWL ontologies resemble high-quality software libraries. They are open source, have a concrete maintainer and community support and are available online.
Sometimes it would be enough to extend an existing ontology rather than create a new one from scratch. When working in a less common domain or given a demanding task you might be unsure whether an appropriate ontology is available. It might be useful to reach out to Linked Data/Semantic Web/Knowledge Graph communities or experienced consultants when in doubt whether an existing ontology for a given project exists.
Time Ontology
In the case of our project, we can rely on the Time Ontology which satisfies all the above criteria of a user-friendly domain ontology. It defines generic categories and properties for modeling and representing temporal aspects in any context. The fact that time is one of the basic aspects of our reality requires usage of high-level, more abstract concepts like instants or intervals. However, to remain applicable in different areas, it avoids introducing too many assumptions and concepts and clearly describes its theoretical outlook. “The basic structure of the ontology is based on an algebra of binary relations on intervals (e.g., meets, overlaps, during) developed by Allen al-84, af-97 for representing qualitative temporal information, and to address the problem of reasoning about such information”. Below is the diagram of the thirteen elementary relations between time periods (proper intervals whose beginning and end are different):
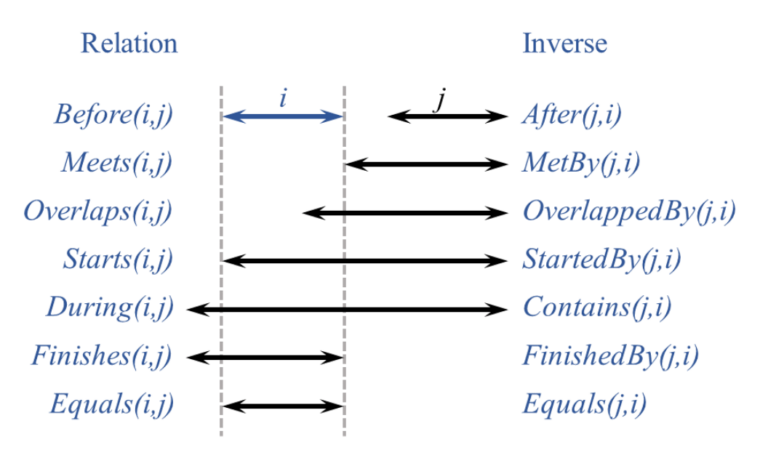
For the scope of this project, we will search through data for the most common interval relations:
- intervalOverlaps
- intervalContains
- intervalMeets
- intervalIn – not shown on the above diagram: (the union of During, Starts and Finishes)
The hyperlinks above refer to the precise definitions of respective interval relations which can be easily translated into SPARQL queries. Since our use case requires modeling temporal intervals but not instants, we can assume each event to analyze has two data properties – start time and end time – each referring to an xsd:date, xsd:dateTime or xsd:dateTimeStamp value3.
Implementation
To enable processing data entirely on the client-side, we decided to choose the Rust programming language to embed the Oxigraph SPARQL engine in a web browser using WebAssembly (Wasm). Since Oxigraph can be used not only as a triplestore server but also as a Rust library, it is a natural choice for implementing a Wasm-driven client-side app transforming raw event data into RDF triples.
To increase the performance of our interval detector, a SPARQL CONSTRUCT query is generated for each event with parametrized start and end timestamps (and not using a single query to analyze the entire dataset).
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX time: <http://www.w3.org/2006/time#>
PREFIX baseUrl: <http://example.data/event/>
CONSTRUCT {?e1 ?timeInterval ?e2.}
WHERE {
?e2 baseUrl:startDate ?st2 ;
baseUrl:endDate ?end2 .
BIND(<http://example.data/event/de105920-461f-495c-bf60-293fc2a45d81> AS ?e1)
FILTER(?e1 != ?e2)
BIND(IF("2001-12-16T02:50:21Z"^^<http://www.w3.org/2001/XMLSchema#dateTime> < ?st2 && "2001-12-17T21:41:58Z"^^<http://www.w3.org/2001/XMLSchema#dateTime> > ?st2 && "2001-12-17T21:41:58Z"^^<http://www.w3.org/2001/XMLSchema#dateTime> < ?end2, time:intervalOverlaps,
IF("2001-12-16T02:50:21Z"^^<http://www.w3.org/2001/XMLSchema#dateTime> < ?st2 && "2001-12-17T21:41:58Z"^^<http://www.w3.org/2001/XMLSchema#dateTime> > ?end2, time:intervalContains,
IF("2001-12-17T21:41:58Z"^^<http://www.w3.org/2001/XMLSchema#dateTime> = ?st2, time:intervalMeets,
IF("2001-12-16T02:50:21Z"^^<http://www.w3.org/2001/XMLSchema#dateTime> >= ?st2 && "2001-12-17T21:41:58Z"^^<http://www.w3.org/2001/XMLSchema#dateTime> <= ?end2
&& !("2001-12-16T02:50:21Z"^^<http://www.w3.org/2001/XMLSchema#dateTime> = ?st2 && "2001-12-17T21:41:58Z"^^<http://www.w3.org/2001/XMLSchema#dateTime> = ?end2), time:intervalIn, -1 )))) AS ?timeInterval)
FILTER(?timeInterval != -1)
} LIMIT 100000
Interval finder demo
The Interval finder demo is available online under https://brox-it.github.io/time-intervals-wasm/.
You can use it with your own data without any restrictions because it does not upload the submitted dataset to any server, but instead processes it internally in your browser. You can start by submitting the predefined example RDF and CSV datasets. Before processing your data, please read the instructions on the demo website to learn how to handle custom properties and bigger datasets.
Submitting the example CSV will result in a response containing each of the supported interval types. Example:
<http://example.data/event/86cb06d8-6304-4589-a94e-989eb2018da3/t3> <http://www.w3.org/2006/time#intervalContains> <http://example.data/event/5a08bb12-d71e-4ddd-ae54-d849e073950a/t4> .
<http://example.data/event/5a08bb12-d71e-4ddd-ae54-d849e073950a/t4> <http://www.w3.org/2006/time#intervalIn> <http://example.data/event/86cb06d8-6304-4589-a94e-989eb2018da3/t3> .
<http://example.data/event/35223804-101c-4a6f-a29f-53af0ccce33f/t1> <http://www.w3.org/2006/time#intervalOverlaps> <http://example.data/event/b27658bd-f783-4def-8070-60b205bc2a9e/t2> .
<http://example.data/event/f3e29ece-a77b-42a6-8df4-c60606463247/d3> <http://www.w3.org/2006/time#intervalIn> <http://example.data/event/97720813-eaf0-43b9-bc53-3c9784bbf88b/d4> .
<http://example.data/event/6e2b9057-c1fe-4596-a317-376ea8938e76/d1> <http://www.w3.org/2006/time#intervalOverlaps> <http://example.data/event/5be13180-813a-4d77-8266-435f70fa750c/d2> .
What can be done with the RDF response? It can be easily shared between various applications and systems. You can use one of the commercial or open-source triplestores to gather analyzed interval data and perform additional data processing or data validation using SPARQL, SHACL or OWL. You could also use Linked Data integration platforms like eccenca Corporate Memory to integrate those results with even more data. Let us know if you need more information.
Conclusion
Semantic Web technologies are not restricted to big projects with big budgets and centralized architecture. This article demonstrates they can be used to solve concrete problems and make producing meaningful data much easier.
Footnotes
KGC 2022 – Ora Lassila, Amazon – Will Knowledge Graphs Save Us From the Mess of Modern Data Practice – „self-describing data with accessible semantics“; Ora Lassila – Graph Abstractions Matter | CDW21 Presentations – support ontologies with predefined libraries (“ontology engines”).
In a simplified way ontologies can be categorized into top-level, domain and specialized ontologies. Top-level or sometimes called upper-level ontologies are extremely broad in its scope targeting to be applicable for each domain which means they try describing the outline for the entire reality (including immaterial things like dispositions, attitudes, roles etc.). While some of their implicit or hidden ontological (or metaphysical) assumptions might fit your worldview and ideas embracing them might lead to making your domain ontology more verbose, less reusable or limit their applicability because of too restrictive and opinionated philosophical assumptions. In most cases the advice is to start with a domain ontology or its specializations (lightweight, task-specific specialized ontologies).
A full, low-level Time Ontology integration would assume a separate pair of start/end instant objects for each interval, which would lead to the creation of many additional triples. Since we want to create a lightweight client-side (web browser) solution, we want to keep the data footprint minimal to avoid unnecessary processing overhead.