Grounding Teil 2/3: RAG & Graph-RAG – Wie KI endlich sinnvolle Antworten liefert
Im ersten Teil unserer Serie haben wir gesehen: Viele KI-Projekte in Unternehmen scheitern, weil sie auf Sprachmodelle setzen, denen das Grounding fehlt – also die Verbindung zu überprüfbaren, unternehmensspezifischen Datenquellen.
Doch wie bringt man Kontext, Relevanz und Nachvollziehbarkeit in ein Sprachmodell wie ChatGPT?
Ein vielversprechender Ansatz nennt sich Retrieval-Augmented Generation – kurz RAG.
Was ist RAG?
Retrieval-Augmented Generation ist ein technisches Konzept, das zwei Welten miteinander verbindet:
Ein Sprachmodell (LLM), das Texte generieren kann,
und eine Wissensquelle, meist in Form einer Vektordatenbank, in der Dokumente oder Textpassagen semantisch auffindbar gemacht wurden.
Wenn eine Nutzeranfrage gestellt wird, durchsucht ein sogenannter Retriever diese Datenbank nach passenden Inhalten. Diese werden dem Sprachmodell als Kontext mitgegeben, sodass es seine Antwort auf diesen „externen Speicher“ stützen kann.
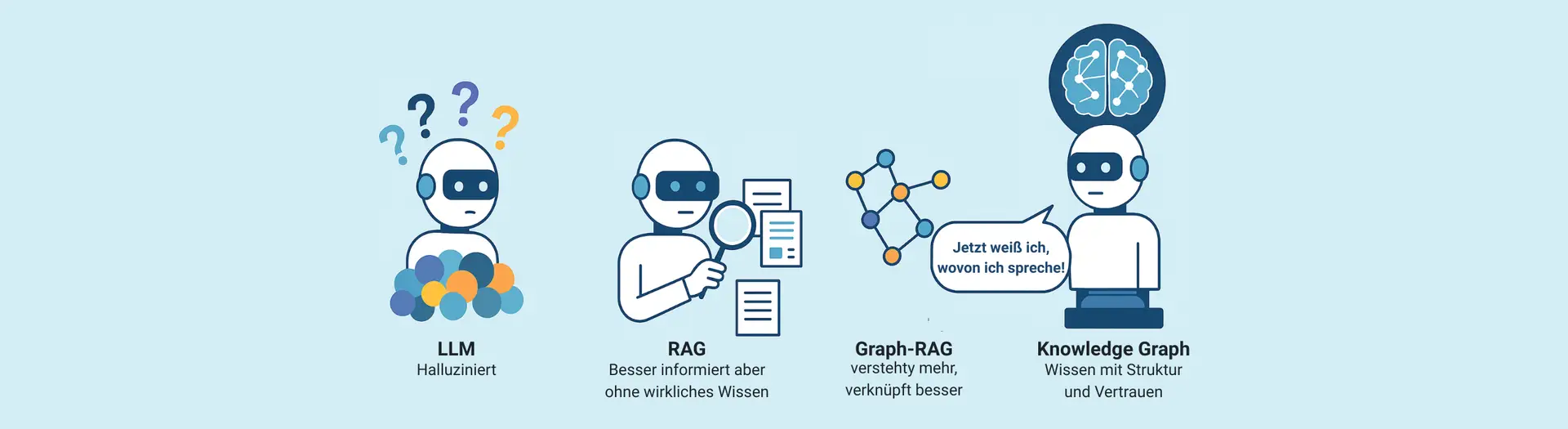
Einfach gesagt: RAG gibt dem Modell das Wissen, das es eigentlich gar nicht hat.
Die Vorteile von RAG
RAG ist ein großer Schritt nach vorn – insbesondere im Vergleich zu reinen LLMs ohne jeglichen Bezug zu unternehmensinternem Wissen. Die wichtigsten Pluspunkte:
- Aktualität und Kontext: Das Modell greift auf aktuelle, firmenspezifische Informationen zu.
- Reduzierte Halluzinationen: Weil echte Dokumente als Grundlage dienen, steigt die inhaltliche Verlässlichkeit.
- Nachvollziehbarkeit: Antworten lassen sich auf konkrete Quelltexte zurückführen – ein Plus für Transparenz und Vertrauen.
Gerade für Unternehmen, die schnell erste Prototypen oder interne Assistenzsysteme aufbauen wollen, bietet RAG eine flexible Möglichkeit mit relativ wenig Vorbereitungsaufwand.
…aber RAG hat Grenzen
So vielversprechend RAG auch klingt – es ist kein Allheilmittel. Denn RAG bringt seine eigenen Schwächen mit:
- Fehlendes Weltverständnis: Der Retriever sucht nach semantisch ähnlichen Textpassagen – versteht aber keine logischen Zusammenhänge oder Widersprüche.
- Nur oberflächlicher Kontext: Die übergebenen Textabschnitte sind oft klein und fragmentiert. Das Gesamtbild fehlt.
- Probleme bei Komplexität: Fragen, die eine übergreifende Aggregation, Interpretation oder Auflösung von Widersprüchen erfordern, überfordern den RAG-Ansatz.
- Starke Abhängigkeit von der Datenqualität: Wenn die Dokumente schlecht strukturiert, redundant oder inkonsistent sind, leidet auch die Qualität der Antwort.
Beispiel: Wenn ein Dokument mehrere widersprüchliche Aussagen enthält (z. B. verschiedene Produktpreise oder Definitionen), kann RAG das nicht auflösen. Das Modell nimmt einfach irgendeinen passenden Abschnitt – oft ohne zu erkennen, dass es sich dabei um veraltete oder falsche Informationen handelt.
→ Ein Fortschritt – aber kein Fundament
RAG ist ein guter und wichtiger Zwischenschritt. Es bringt Sprachmodelle näher an reale Unternehmensdaten, erhöht die Relevanz der Antworten und eröffnet spannende Use Cases.
Doch für verlässliche, skalierbare und erklärbare KI-Lösungen reicht es nicht aus. Denn RAG weiß nicht, was es da eigentlich liest. Es erkennt keine Beziehungen, keine logischen Abhängigkeiten, keine Widersprüche.
Deshalb braucht es mehr: Struktur. Kontext. Kuration. Und genau das liefern Graph-RAG und Knowledge Graphen – unser Thema im dritten und letzten Teil dieser Serie: Grounding Teil 3/3: Graph-RAG und Knowledge Graphen – Wie KI endlich verlässlich wird.

Autorin
Sophie Mitterweger

Co-Autor
Christian Beil
Haben wir Ihr Interesse geweckt?
Lassen Sie uns ins Gespräch kommen
Data & AI
- Christian Beil
- +49 173 3969 952
- cbeil@brox.de