Grounding Teil 3/3: Graph-RAG und Knowledge Graphen – Wie KI endlich verlässlich wird
Im vorherigen Teil haben wir gesehen:
Viele Unternehmen setzen inzwischen auf Sprachmodelle wie ChatGPT, um Informationen zu verarbeiten, interne Prozesse zu unterstützen oder Wissen zugänglich zu machen. Doch sobald es um verlässliche, nachvollziehbare und kontextbewusste Aussagen geht, stoßen diese Modelle schnell an ihre Grenzen – selbst wenn sie mit internen Daten angereichert werden.
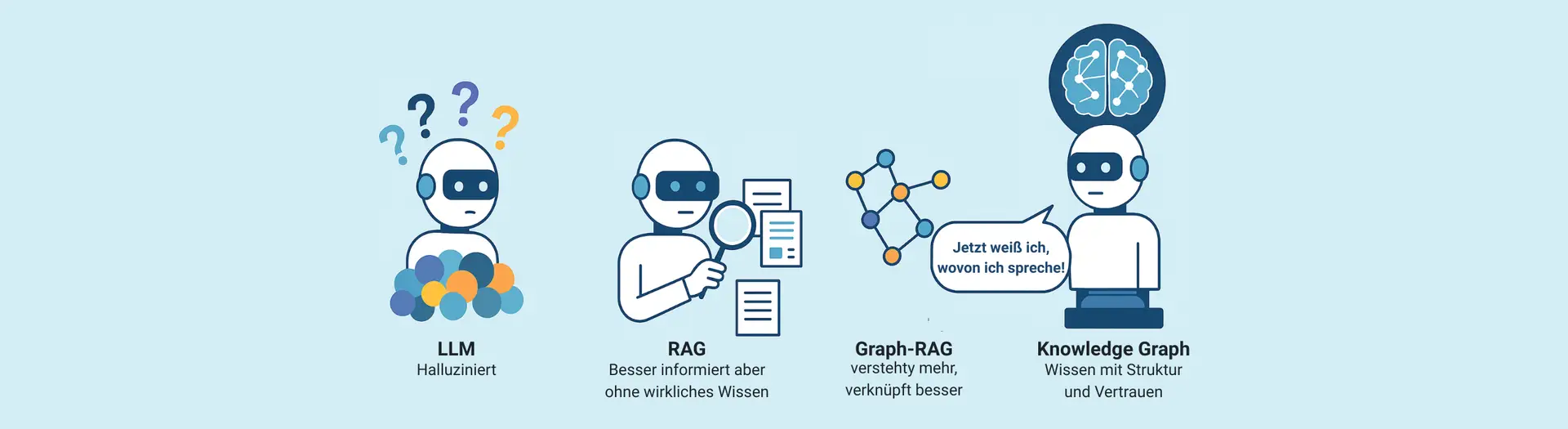
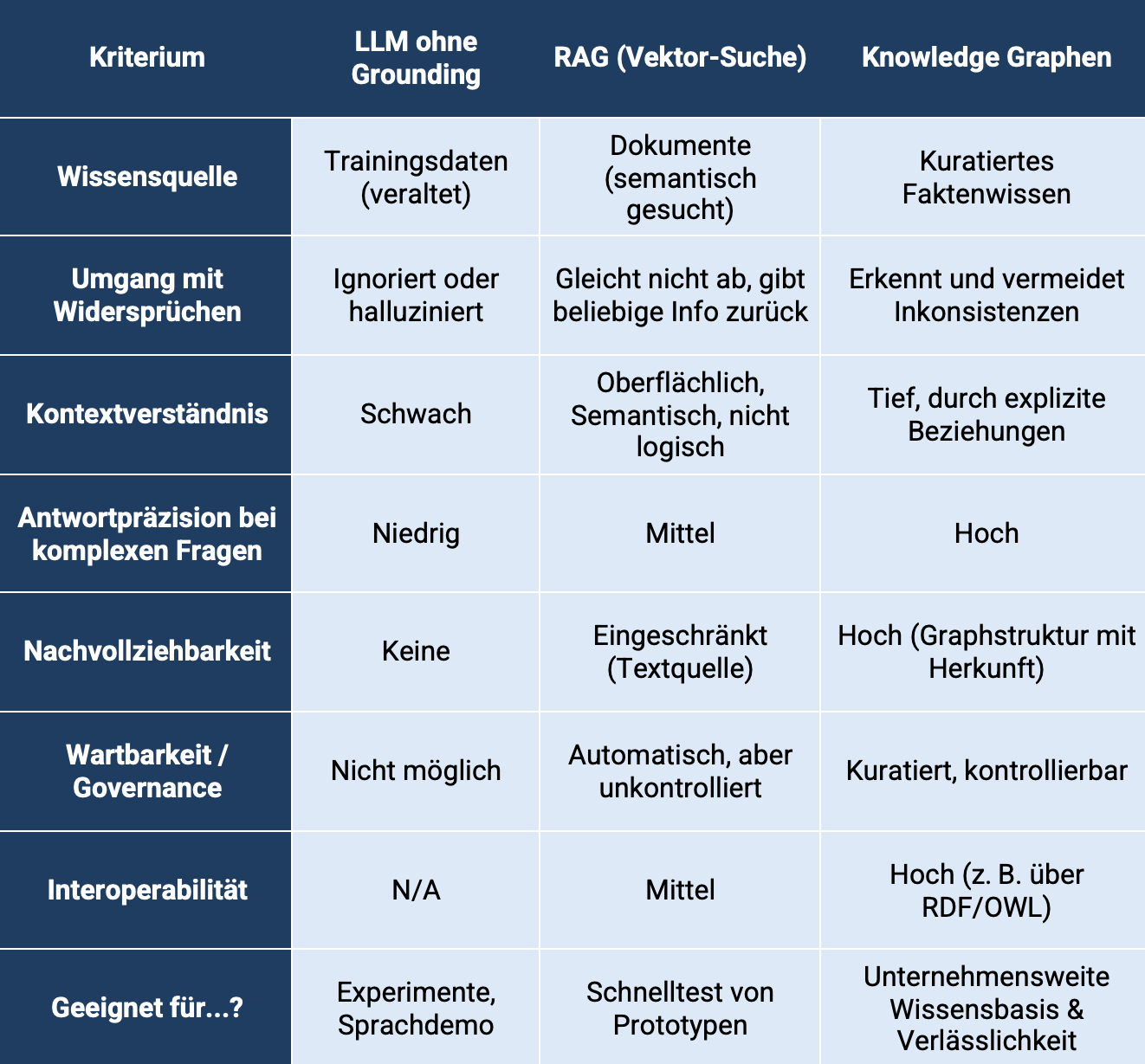
Retrieval-Augmented Generation (RAG) war ein erster Versuch, diesem Problem zu begegnen: Sprachmodelle werden mit unternehmensinternen Dokumenten kombiniert, um relevantere Antworten zu liefern. Doch auch RAG stößt bei komplexen Fragestellungen und fehlender Struktur an seine Grenzen und ist weniger Fundament, eher ein Brückenschlag, denn: Es fehlt an tiefem Kontextverständnis, logischer Struktur und der Fähigkeit, Inkonsistenzen zu erkennen.
Der nächste Entwicklungsschritt heißt deshalb Graph-RAG – und langfristig: Knowledge Graphen. Sie bringen Ordnung ins Wissenschaos und ermöglichen eine neue Qualität von KI-Anwendungen.
Was ist Graph-RAG?
Graph-RAG verbindet das Beste aus zwei Welten: die Flexibilität von Sprachmodellen mit der strukturellen Tiefe eines Knowledge Graphen.
Statt nur einzelne Textabschnitte aus Dokumenten zu suchen (wie bei klassischem RAG), wird bei Graph-RAG Wissen extrahiert, semantisch verknüpft und in einem Graphen organisiert. Das Modell kann so auf eine strukturierte, vernetzte Datenbasis zugreifen – und dabei Zusammenhänge erkennen, Themen clustern, Widersprüche auflösen und präziser antworten.
Vorteile von Graph-RAG:
- Erkennt semantische Beziehungen zwischen Inhalten.
- Bietet thematisch vollständige und aggregierte Antworten.
- Spart Rechenkosten (weniger irrelevante Kontext-Tokens).
- Aggregiert Wissen aus vielen Quellen konsistent.
- Liefert nachvollziehbare Antworten mit Herkunftsangabe.
Kurz gesagt: Graph-RAG denkt vernetzter und antwortet schlauer.
Der Königsweg: Kuratiertes Wissen im Knowledge Graph
Während Graph-RAG bereits ein bedeutender Fortschritt ist, geht der Ansatz mit Knowledge Graphen noch einen entscheidenden Schritt weiter: Hier wird Wissen nicht nur extrahiert – sondern kuratiert, strukturiert und gepflegt.
Ein Knowledge Graph ist ein semantisches Netz aus:
- Entitäten (Knoten) wie Produkte, Personen, Prozesse, Orte etc.
- Beziehungen (Kanten), die diese Entitäten logisch miteinander verknüpfen.
Das bedeutet: Unternehmen bauen sich mit einem Knowledge Graph ihr eigenes, zuverlässiges Wissensmodell – das exakt auf ihre Fachdomäne zugeschnitten ist.
Die Vorteile:
- Explizite Bedeutungen und Relationen: Kein Interpretationsspielraum, sondern Klarheit.
- Widerspruchsfreiheit: Wissen wird redaktionell gepflegt – inkonsistente Informationen werden erkannt und ausgeschlossen.
- Erklärbarkeit: Jede Antwort lässt sich logisch und visuell im Graph nachvollziehen.
- Governance & Skalierbarkeit: Wissen lässt sich kontrollieren, versionieren und gezielt erweitern.
- Interoperabilität: Knowledge Graphen arbeiten standardisiert (z. B. via RDF, OWL) und können mit anderen Systemen interagieren.
→ Struktur schlägt Semantik
Wer heute KI im Unternehmen ernsthaft einsetzen will, braucht mehr als ein Sprachmodell. Denn Sprache ist nur die Oberfläche – Wissen ist das Fundament.
RAG ist ein Einstieg – schnell, flexibel, aber begrenzt.
Graph-RAG bringt mehr Tiefe, Verständnis und Präzision.
Knowledge Graphen liefern die Grundlage für verlässliche, erklärbare, langfristig wartbare KI-Systeme.
LLMs sind das Sprachzentrum – Knowledge Graphen die linke Gehirnhälfte der KI.
Nur in Kombination entsteht etwas wirklich Nützliches: Eine KI, die nicht nur gut klingt, sondern weiß, wovon sie spricht.

Autorin
Sophie Mitterweger

Co-Autor
Christian Beil
Haben wir Ihr Interesse geweckt?
Lassen Sie uns ins Gespräch kommen
Data & AI
- Christian Beil
- +49 173 3969 952
- cbeil@brox.de